Pandas
数据结构简介
1、Series
import numpy as np,pandas as pd
arr1 = np.arange(10)
print(arr1)
print(type(arr1))- 通过一维数组创建
s1 = pd.Series(arr1)
print(s1)
print(type(s1))结果:
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9- 通过字典创建
dic = {'a':10,'b':20,'c':30,'d':40}
s2 = pd.Series(dic)
print(s2)结果:
a 10
b 20
c 30
d 402、DataFrame
- 二维数组创建数据框
arr2 = np.array(np.arange(12)).reshape(4,3)
print(arr2)
df1 = pd.DataFrame(arr2)
print(df1)结果:
0 1 2
0 0 1 2
1 3 4 5
2 6 7 8
3 9 10 11- 字典创建数据框
dic2 = {'a':[1,2,3,4],'b':[5,6,7,8],'c':[9,0,11,21]}
print(dic2)
df2 = pd.DataFrame(dic2)
print(df2)
dic3 = {'one':{'a':1,'b':2,'c':3,'d':4},'two':{'a':5,'b':6,'c':7,'d':8},'three':{'a':9,'b':10,'c':11,'d':12}}
df3 = pd.DataFrame(dic3)
print(df3)结果:
{'a': [1, 2, 3, 4], 'b': [5, 6, 7, 8], 'c': [9, 0, 11, 21]}
a b c
0 1 5 9
1 2 6 0
2 3 7 11
3 4 8 21
one two three
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12通过数据框的方式创建数据框
df4 = df3[['one','two']]
print(df4)结果:
one two
a 1 5
b 2 6
c 3 7
d 4 8#数据索引 index
##通过索引值或索引标签获取数据
s4 = pd.Series(np.array(np.arange(5)))
print(s4)
print(s4.index)
s4.index = ['a','b','c','d','e']
print(s4)
print(s4[3],s4['a'])结果:
0 0
1 1
2 2
3 3
4 4
dtype: int32
RangeIndex(start=0, stop=5, step=1)
a 0
b 1
c 2
d 3
e 4
dtype: int32
3 0自动化对齐
s5=pd.Series(np.array([1,2,3,21,12,325]),index=['a','b','c','d','e','f'])
print(s5)
s6=pd.Series(np.array([1,2,3,21,12,325]),index=['b','b','c','d','e','f'])
print(s5+s6)结果:
a 1
b 2
c 3
d 21
e 12
f 325
dtype: int32
a NaN
b 3.0
b 4.0
c 6.0
d 42.0
e 24.0
f 650.0
dtype: float64利用pandas查询数据
导入数据
import pandas as pd
stu_dic = {'Age':[14,13,13,14,14,12,12,15,13,12,11,14,12,15,16,12,15,11,15],
'Height':[69,56.5,65.3,62.8,63.5,57.3,59.8,62.5,62.5,59,51.3,64.3,56.3,66.5,72,64.8,67,57.5,66.5],
'Name':['Alfred','Alice','Barbara','Carol','Henry','James','Jane','Janet','Jeffrey','John','Joyce','Judy','Louise','Marry','Philip','Robert','Ronald','Thomas','Willam'],
'Sex':['M','F','F','F','M','M','F','F','M','M','F','F','F','F','M','M','M','M','M'],
'Weight':[112.5,84,98,102.5,102.5,83,84.5,112.5,84,99.5,50.5,90,77,112,150,128,133,85,112]}
student = pd.DataFrame(stu_dic)-
print(student.head())
print(student.tail())
print(student.loc[[1,3,4,5]])
print(student[['Name']].head())
print(student.loc[:3,['Name']])
print(student[(student['Sex']=='M') & (student['Age']>14)])
print(student[(student['Sex']=='M') & (student['Age']>14)][['Name']])结果:
Age Height Name Sex Weight
0 14 69.0 Alfred M 112.5
1 13 56.5 Alice F 84.0
2 13 65.3 Barbara F 98.0
3 14 62.8 Carol F 102.5
4 14 63.5 Henry M 102.5
Age Height Name Sex Weight
14 16 72.0 Philip M 150.0
15 12 64.8 Robert M 128.0
16 15 67.0 Ronald M 133.0
17 11 57.5 Thomas M 85.0
18 15 66.5 Willam M 112.0
Age Height Name Sex Weight
1 13 56.5 Alice F 84.0
3 14 62.8 Carol F 102.5
4 14 63.5 Henry M 102.5
5 12 57.3 James M 83.0
Name
0 Alfred
1 Alice
2 Barbara
3 Carol
4 Henry
Name
0 Alfred
1 Alice
2 Barbara
3 Carol
Age Height Name Sex Weight
14 16 72.0 Philip M 150.0
16 15 67.0 Ronald M 133.0
18 15 66.5 Willam M 112.0
Name
14 Philip
16 Ronald
18 Willam利用pandas的DataFrames进行统计分析
np.random.seed(1234)
d1 = pd.Series(2*np.random.normal(size = 100)+3)
d2 = np.random.f(2,4,size = 100)
d3 = np.random.randint(1,100,size = 100)
print(d1)
print(d2)
print(d3)
print('非空元素计算: ', d1.count()) #非空元素计算
print('最小值: ', d1.min()) #最小值
print('最大值: ', d1.max()) #最大值
print('最小值的位置: ', d1.idxmin()) #最小值的位置,类似于R中的which.min函数
print('最大值的位置: ', d1.idxmax()) #最大值的位置,类似于R中的which.max函数
print('10%分位数: ', d1.quantile(0.1)) #10%分位数
print('求和: ', d1.sum()) #求和
print('均值: ', d1.mean()) #均值
print('中位数: ', d1.median()) #中位数
print('众数: ', d1.mode()) #众数
print('方差: ', d1.var()) #方差
print('标准差: ', d1.std()) #标准差
print('平均绝对偏差: ', d1.mad()) #平均绝对偏差
print('偏度: ', d1.skew()) #偏度
print('峰度: ', d1.kurt()) #峰度
print('描述性统计指标: ', d1.describe()) #一次性输出多个描述性统计指标结果:
非空元素计算: 100
最小值: -4.1270333212494705
最大值: 7.781921030926066
最小值的位置: 81
最大值的位置: 39
10%分位数: 0.6870184644069928
求和: 307.0224566250873
均值: 3.070224566250874
中位数: 3.204555266776845
众数: 0 -4.127033
1 -1.800907
2 -1.485370
3 -1.149955
4 -1.042510
5 -0.634054
6 -0.093811
7 0.108380
8 0.196053
9 0.618049
10 0.694682
11 0.714737
12 0.862022
13 0.944299
14 1.051527
15 1.147491
16 1.205686
17 1.429130
18 1.558823
19 1.688061
20 1.726953
21 1.830564
22 1.867108
23 1.903515
24 1.976237
25 2.061389
26 2.139809
27 2.200071
28 2.204320
29 2.310468
...
70 4.131477
71 4.263959
72 4.351108
73 4.408456
74 4.409441
75 4.510828
76 4.534737
77 4.633188
78 4.682018
79 4.683349
80 4.719177
81 4.727435
82 4.774326
83 4.906648
84 4.969840
85 4.983892
86 5.067601
87 5.091877
88 5.095157
89 5.117938
90 5.300071
91 5.636303
92 5.642211
93 5.642316
94 5.783972
95 5.865414
96 6.091318
97 7.015686
98 7.061207
99 7.781921
Length: 100, dtype: float64
方差: 4.005609378535085
标准差: 2.0014018533355777
平均绝对偏差: 1.5112880411556109
偏度: -0.6494780760484293
峰度: 1.2201094052398012
描述性统计指标: count 100.000000
mean 3.070225
std 2.001402
min -4.127033
25% 2.040101
50% 3.204555
75% 4.434788
max 7.781921
dtype: float64利用pandas实现SQL操作
dic = {'Name':['LiuShunxiang','Zhangshan'],'Sex':['M','F'],'Age':[27,23],'Height':[165.7,167.2],'Weight':[61,63]}
student2 = pd.DataFrame(dic)
print(student2)增
student3 = pd.concat([student,student2])
print(student3)
#新增一列
print(pd.DataFrame(student2, columns=['Age','Height','Name','Sex','Weight','Score']))删
del(student3)
print(student3)
#删除指定行
print(student.drop([0,3,5,1]))
#删除指定列
print(student.drop(['Height','Weight'],axis=1).head())#利用pandas进行缺失值的处理
df = pd.DataFrame([[1,1,2],[3,5,np.nan],[13,21,34],[55,np.nan,10],[np.nan,np.nan,np.nan],[np.nan,1,2]],columns=('x1','x2','x3'))
print(df)
#直接删除
print(df.dropna())
#用0填充
print(df.fillna(0))
########
print("采用前倾填充、向后填充")
##采用前倾填充、向后填充
print(df.fillna(method='ffill'))
print(df.fillna(method='bfill'))
#######
print("#用常量填充不同的列")
#用常量填充不同的列
x1_median=df['x1'].median()
x2_mean=df['x2'].mean()
x3_mean=df['x3'].mean()
print(x1_median)
print(x2_mean)
print(x3_mean)
print(df.fillna({'x1':x1_median,'x2':x2_mean,'x3':x3_mean}))结果:
x1 x2 x3
0 1.0 1.0 2.0
1 3.0 5.0 NaN
2 13.0 21.0 34.0
3 55.0 NaN 10.0
4 NaN NaN NaN
5 NaN 1.0 2.0
x1 x2 x3
0 1.0 1.0 2.0
2 13.0 21.0 34.0
x1 x2 x3
0 1.0 1.0 2.0
1 3.0 5.0 0.0
2 13.0 21.0 34.0
3 55.0 0.0 10.0
4 0.0 0.0 0.0
5 0.0 1.0 2.0
采用前倾填充、向后填充
x1 x2 x3
0 1.0 1.0 2.0
1 3.0 5.0 2.0
2 13.0 21.0 34.0
3 55.0 21.0 10.0
4 55.0 21.0 10.0
5 55.0 1.0 2.0
x1 x2 x3
0 1.0 1.0 2.0
1 3.0 5.0 34.0
2 13.0 21.0 34.0
3 55.0 1.0 10.0
4 NaN 1.0 2.0
5 NaN 1.0 2.0
#用常量填充不同的列
8.0
7.0
12.0
x1 x2 x3
0 1.0 1.0 2.0
1 3.0 5.0 12.0
2 13.0 21.0 34.0
3 55.0 7.0 10.0
4 8.0 7.0 12.0
5 8.0 1.0 2.0#利用pandas实现Excel的数据透视表功能
Table2 = pd.pivot_table(student, values=['Height','Weight'], columns=['Sex','Age']).unstack()
print(Table2)结果:
Age 11 12 13 14 15 16
Sex
Height F 51.3 58.050000 60.9 63.55 64.50 NaN
M 57.5 60.366667 62.5 66.25 66.75 72.0
Weight F 50.5 80.750000 91.0 96.25 112.25 NaN
M 85.0 103.500000 84.0 107.50 122.50 150.0-
Table2 = pd.pivot_table(student, values=['Height','Weight'], columns=['Sex','Age'],aggfunc=[np.mean,np.median,np.std]).unstack()
print(Table2)结果:
mean median \
Age 11 12 13 14 15 16 11 12 13
Sex
Height F 51.3 58.050000 60.9 63.55 64.50 NaN 51.3 58.05 60.9
M 57.5 60.366667 62.5 66.25 66.75 72.0 57.5 59.00 62.5
Weight F 50.5 80.750000 91.0 96.25 112.25 NaN 50.5 80.75 91.0
M 85.0 103.500000 84.0 107.50 122.50 150.0 85.0 99.50 84.0
std \
Age 14 15 16 11 12 13 14
Sex
Height F 63.55 64.50 NaN NaN 2.474874 6.222540 1.060660
M 66.25 66.75 72.0 NaN 3.932345 NaN 3.889087
Weight F 96.25 112.25 NaN NaN 5.303301 9.899495 8.838835
M 107.50 122.50 150.0 NaN 22.765105 NaN 7.071068
Age 15 16
Sex
Height F 2.828427 NaN
M 0.353553 NaN
Weight F 0.353553 NaN
M 14.849242 NaN 多层索引的使用
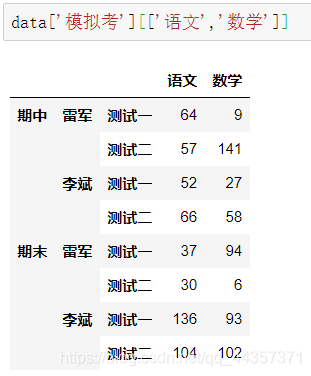
data = pd.DataFrame(np.random.randint(0,150,size=(8,12)),
columns = pd.MultiIndex.from_product([['模拟考','正式考'],
['数学','语文','英语','物理','化学','生物']]),
index = pd.MultiIndex.from_product([['期中','期末'],
['雷军','李斌'],
['测试一','测试二']]))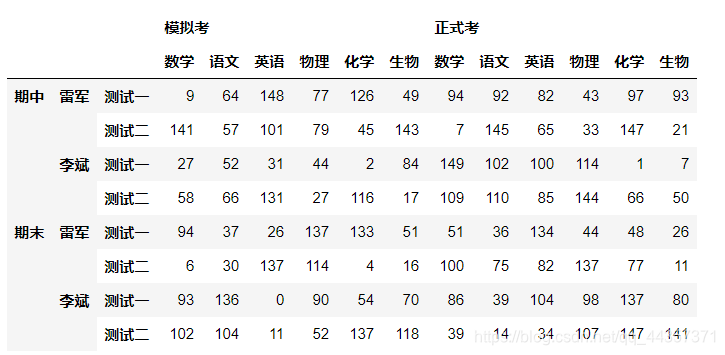
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2470290795@qq.com
文章标题:Pandas
文章字数:2.5k
本文作者:runze
发布时间:2020-02-01, 09:58:53
最后更新:2020-02-01, 16:48:27
原始链接:http://yoursite.com/2020/02/01/%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98/pandas/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

