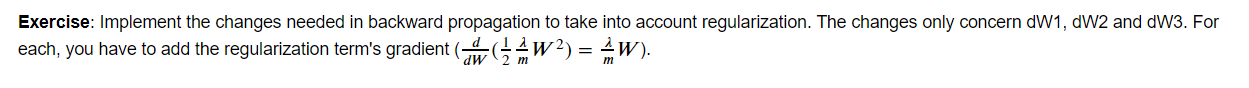grads = {} costs = [] # to keep track of the cost m = X.shape[1] # number of examples layers_dims = [X.shape[0], 20, 3, 1] # Initialize parameters dictionary. parameters = initialize_parameters(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID. if keep_prob == 1: a3, cache = forward_propagation(X, parameters) elif keep_prob < 1: a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob) # Cost function if lambd == 0: cost = compute_cost(a3, Y) else: cost = compute_cost_with_regularization(a3, Y, parameters, lambd) # Backward propagation. assert(lambd==0or keep_prob==1) # it is possible to use both L2 regularization and dropout, # but this assignment will only explore one at a time if lambd == 0and keep_prob == 1: grads = backward_propagation(X, Y, cache) elif lambd != 0: grads = backward_propagation_with_regularization(X, Y, cache, lambd) elif keep_prob < 1: grads = backward_propagation_with_dropout(X, Y, cache, keep_prob) # Update parameters. parameters = update_parameters(parameters, grads, learning_rate) # Print the loss every 10000 iterations if print_cost and i % 10000 == 0: print("Cost after iteration {}: {}".format(i,cost)) if print_cost and i % 1000 == 0: costs.append(cost) # plot the cost plt.plot(costs) plt.ylabel('cost') plt.xlabel('iterations (x1,000)') plt.title("Learning rate =" + str(learning_rate)) plt.show() return parameters
1 2 3 4 5
parameters = model(train_X, train_Y) print ("On the training set:") predictions_train = predict(train_X, train_Y, parameters) print ("On the test set:") predictions_test = predict(test_X, test_Y, parameters)
Cost after iteration 0: 0.6557412523481002
Cost after iteration 10000: 0.1632998752572419
Cost after iteration 20000: 0.13851642423239133
On the training set:
Accuracy: 0.9478672985781991
On the test set:
Accuracy: 0.915