1深度学习的实用层面

参考文章:https://zhuanlan.zhihu.com/p/29794318
1、训练、验证、测试集
对于一组data,我们通常分为:
- 训练集(train set):用训练集对算法或模型进行训练
- 验证集(development set):用验证集(简单交叉验证集hold-out cross validation set)进行交叉验证,选出最好的模型
- 测试集(test set):对模型进行测试,获取模型运行的无偏估计
小数据时代:
例如:100、1000、10000的数据量,可将data分为:
- 无验证集:70% / 30%
- 有验证集:60% / 20% / 20%
大数据时代
验证集的目的是为了验证不同的算法哪种更加有效,所以验证集只要足够大能够验证大约2-10种算法哪种更好就足够了,不需要使用20%的数据作为验证集。如百万数据中抽取1万的数据作为验证集就可以了。
测试集的主要目的是评估模型的效果,如在单个分类器中,往往在百万级别的数据中,我们选择其中1000条数据足以评估单个模型的效果。
- 100万数据量:98% / 1% / 1%;
- 超百万数据量:99.5% / 0.25% / 0.25%(或者99.5% / 0.4% / 0.1%)
Notation
- 建议验证和测试集来自同一分布,这样可以使机器学习算法变得更快
- 如果不需要无偏估计来评估模型的性能,则可以不需要测试集
2、偏差、方差
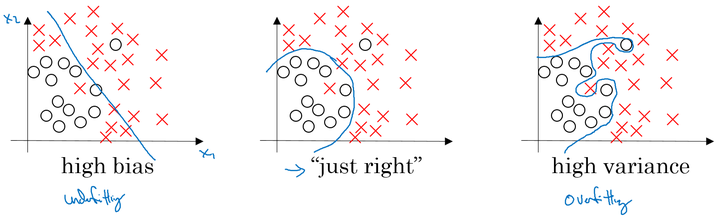
从图中可以看出,在欠拟合时,会出现高偏差(high bias),在过拟合时,会出现高方差(high variance)
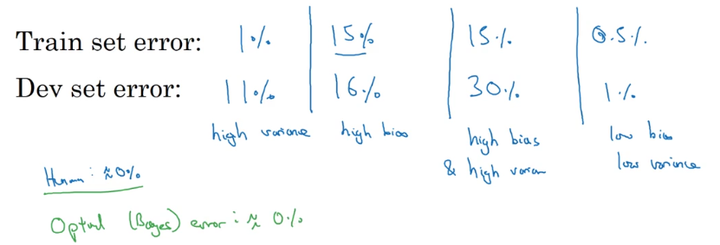
对于1% / 11% 说明过拟合,使训练集误差小,而测试集误差偏大。
但是这是以人眼的误差为0%为基础,若人眼是 15% , 则第二种是较好的情况
对于第三种高偏差、高方差: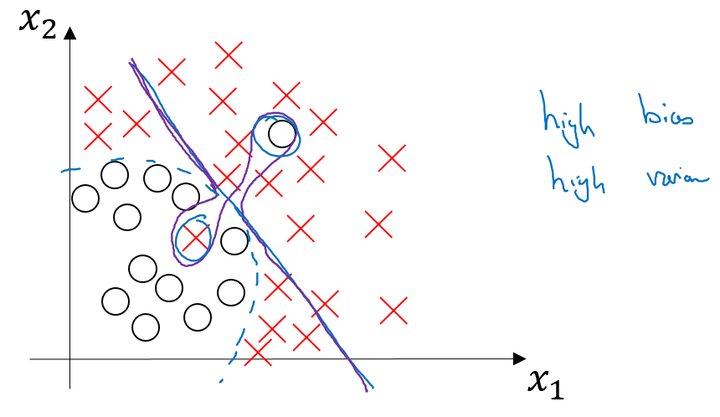
用了线性方程,并且还出现了过拟合
3、机器学习基础
如何解决high bias\high variance?
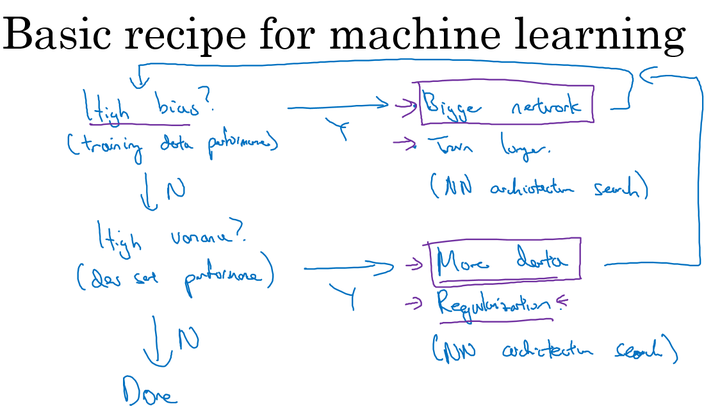
high bias
- 增加网络结构,如增加隐藏层数目;
- 训练更长时间;
- 寻找合适的网络架构,使用更大的NN结构;
high variance
- 获取更多的数据;
- 正则化( regularization);
- 寻找合适的网络结构;
通常情况下,减少一方,会使另一方增加。
但在大数据时代,我们可以通过上面的方法减少一方,而不影响另一方
4、正则化
上面已说,正则化可以降低variance方差
- logistics regression
加入正则化项的代价函数:
L2正则化:
L1正则化:
其中的λ为正则化因子
注意:lambda 在python中属于保留字,所以在编程的时候,用“lambd”代表这里的正则化因子λ。
- Neural Network
加入正则化项的代价函数:
其中),因为W的大小为
,该矩阵范数被称为“Frobenius norm”。
- Weight decay 权重衰减
加入正则化后,梯度变为:
则梯度更新公式变为:
代入得:
其中, 为一个
的项,会给原来的
一个衰减的参数,所以L2范数正则化也被称为“权重衰减(Weight decay)”。
5、为什么正则化可以减少过拟合
对于神经网络得cost function:
当正则化因子λ足够大,为了使cost function变小,则会使w变小趋近于0,则相当于消除了很多神经元的影响,那么图中的大的神经网络就会变成一个较小的网络。
但是实际上隐藏层的神经元依然存在,但是他们的影响变小了,便不会导致过拟合。
数学解释:
假设激活函数为tanh
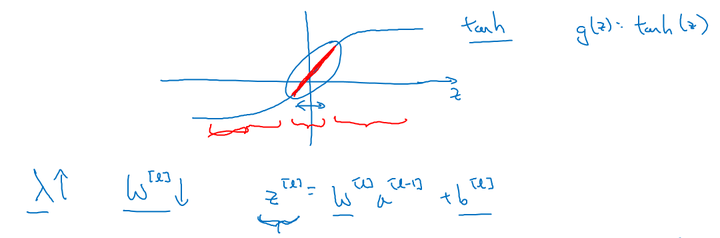
加入正则化项后,当 λ 增大,导致 减小,
便会减小,由上图可知,在 z 较小的区域里,
函数近似线性,所以每层的函数就近似线性函数,整个网络就成为一个简单的近似线性的网络,从而不会发生过拟合。
6、Dropout正则化
Dropout(随机失活)就是在神经网络的Dropout层,为每个神经元结点设置一个随机消除的概率,对于保留下来的神经元,我们得到一个节点较少,规模较小的网络进行训练。
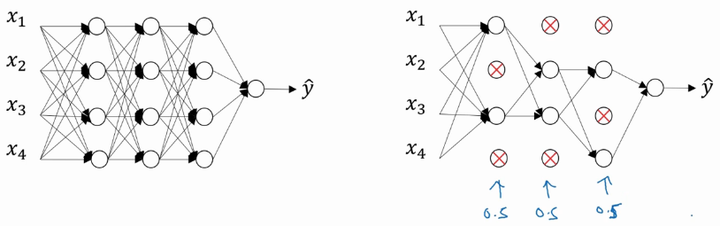
实现Dropout的方法:反向随机失活(Inverted dropout)
首先假设对 layer 3 进行dropout:
keep_prob = 0.8 # 设置神经元保留概率
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob
a3 = np.multiply(a3, d3)
a3 /= keep_prob这里解释下为什么要有最后一步:a3 /= keep_prob
依照例子中的 keep_prob = 0.8 ,那么就有大约20%的神经元被删除了,也就是说 中有20%的元素被归零了,在下一层的计算中有
,所以为了不影响
的期望值,所以需要
的部分除以一个keep_prob。
Inverted dropout 通过对“a3 /= keep_prob”,则保证无论 keep_prob 设置为多少,都不会对的期望值产生影响。
Notation:在测试阶段不要用dropout,因为那样会使得预测结果变得随机。
7、理解Dropout
我们以单个神经元入手,单个神经元的工作就是接收输入,并产生一些有意义的输出,但是加入了Dropout以后,输入的特征都是有可能会被随机清除的,所以该神经元不会再特别依赖于任何一个输入特征,也就是说不会给任何一个输入设置太大的权重。
所以通过传播过程,dropout将产生和L2范数相同的收缩权重的效果。
对于不同的层,设置的keep_prob也不同,一般来说神经元较少的层,会设 keep_prob=1.0,神经元多的层,则会将keep_prob设置的较小。
Dropout 缺点:
dropout的一大缺点就是其使得 Cost function不能再被明确的定义,以为每次迭代都会随机消除一些神经元结点,所以我们无法绘制出每次迭代下降的图,如下:
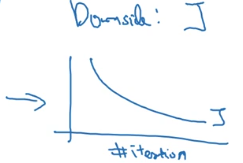
使用Dropout:
关闭dropout功能,即设置 keep_prob = 1.0;
运行代码,确保函数单调递减;
再打开 dropout 。
8、其他正则化方法
- 数据扩增:通过变换图片,得到更多的训练集和验证集
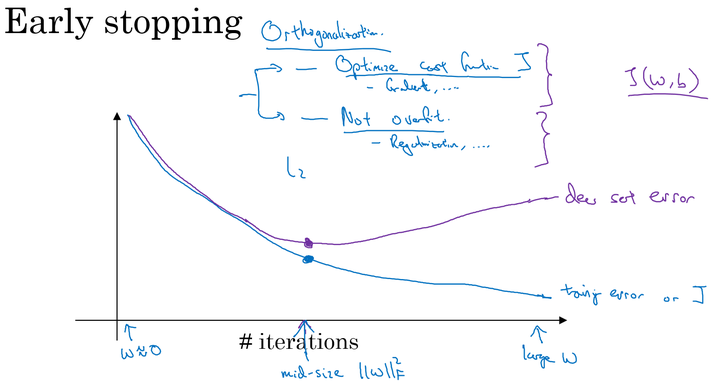
- Early stopping:在交叉验证集的误差上升之前的点停止迭代,避免过拟合。这种方法的缺点是无法同时解决bias和variance之间的最优。
9、归一化输入
对数据集特征 归一化的过程:
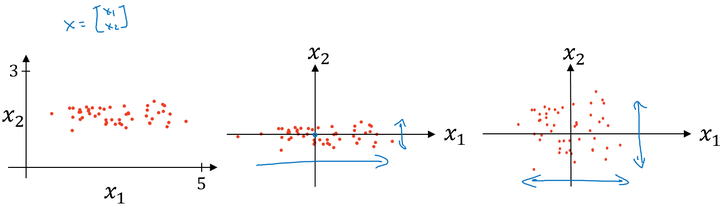
- 计算每个特征所有样本数据的均值:
;
- 减去均值得到对称的分布:
;
- 归一化方差:
,
。
使用归一化原因:
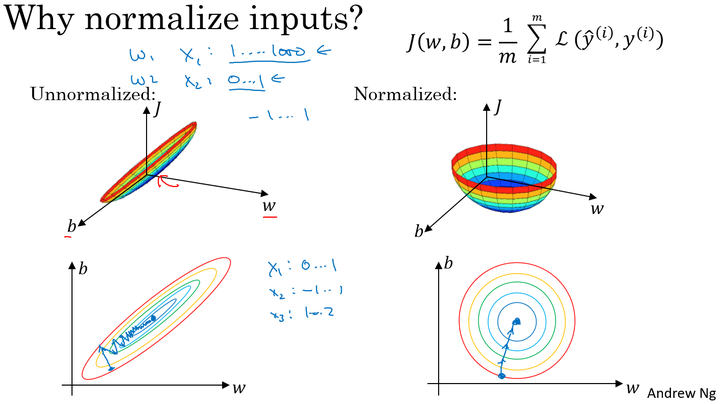
由图可以看出不使用归一化和使用归一化前后 Cost function 的函数形状会有很大的区别。
在不使用归一化的代价函数中,如果我们设置一个较小的学习率,那么很可能我们需要很多次迭代才能到达代价函数全局最优解;如果使用了归一化,那么无论从哪个位置开始迭代,我们都能以相对很少的迭代次数找到全局最优解。
10、梯度消失、梯度爆炸
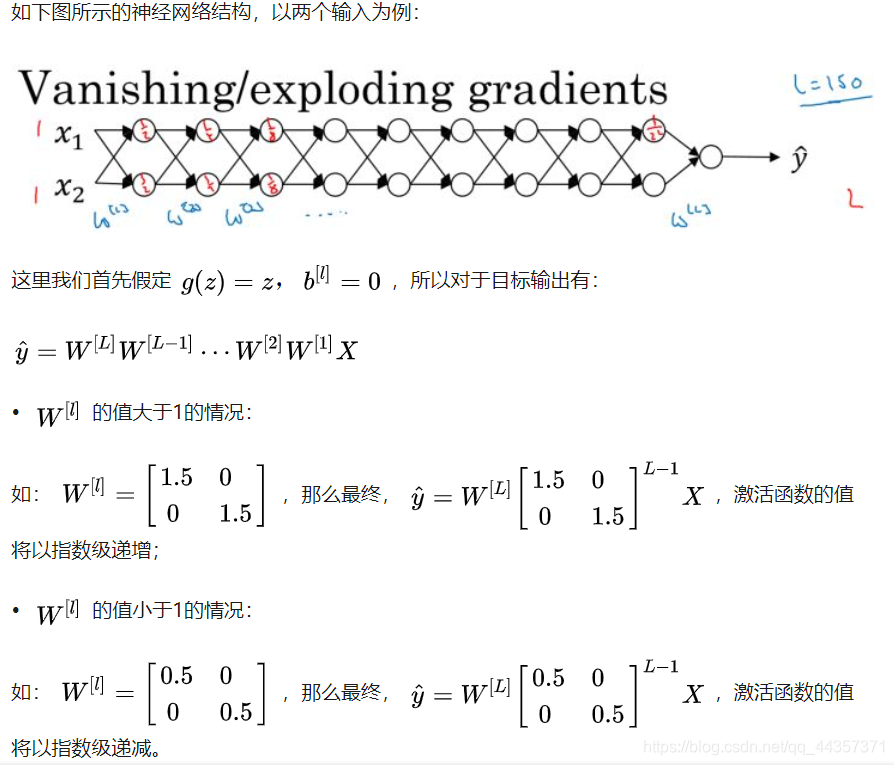
上面的情况对于导数也是同样的道理,所以在计算梯度时,根据情况的不同,梯度函数会以指数级递增或者递减,导致训练导数难度上升,梯度下降算法的步长会变得非常非常小,需要训练的时间将会非常长。
在梯度函数上出现的以指数级递增或者递减的情况就分别称为梯度爆炸或者梯度消失。
11、利用初始化缓解梯度消失和爆炸问题
以一个单神经元为例:
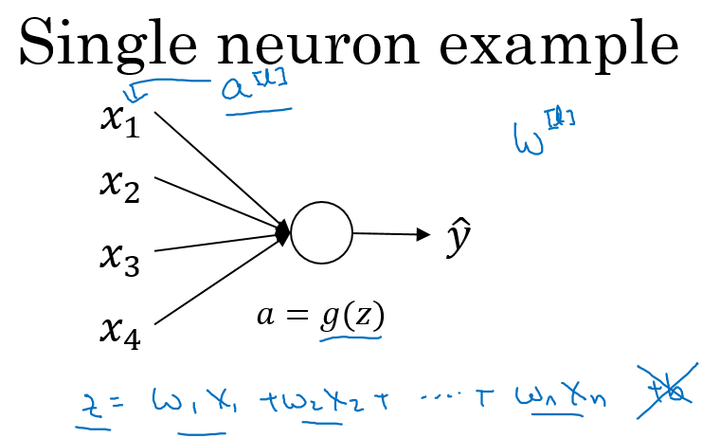
当输入的数量 较大时,我们希望每个
的值都小一些,这样它们的和得到的! 也较小。
这里为了得到较小的 ,设置
,这里称为Xavier initialization。
对参数进行初始化:
WL = np.random.randn(WL.shape[0],WL.shape[1])* np.sqrt(1/n)这么做是因为,如果激活函数的输入 x 近似设置成均值为0,标准方差1的情况,输出 z 也会调整到相似的范围内。虽然没有解决梯度消失和爆炸的问题,但其在一定程度上确实减缓了梯度消失和爆炸的速度。
不同激活函数的 Xavier initialization:
- 激活函数使用Relu:
- 激活函数使用tanh:
其中n是输入的神经元个数,也就是 。
12、梯度的数值逼近
使用双边误差的方法去逼近导数:

由图可以看出,双边误差逼近的误差是0.0001,先比单边逼近的误差0.03,其精度要高了很多。
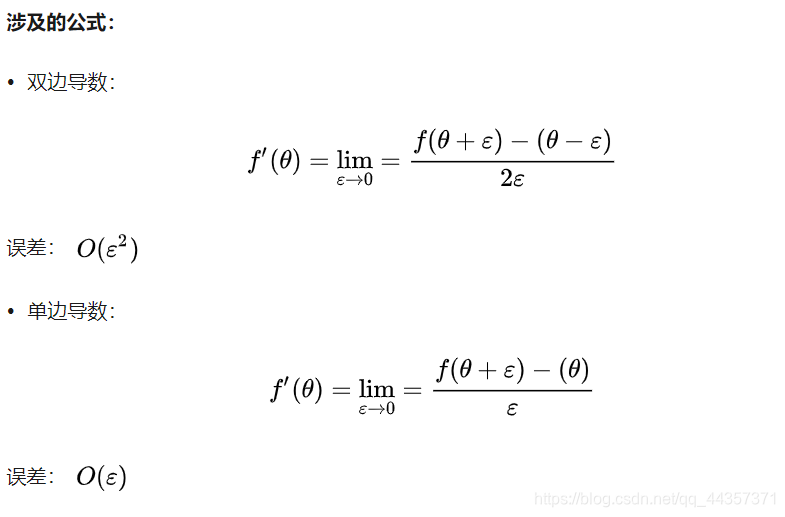
13、梯度检验
连接参数:
因为我们的神经网络中含有大量的参数: ,为了做梯度检验,需要将这些参数全部连接起来,reshape成一个大的向量 θ 。
同时对 执行同样的操作:
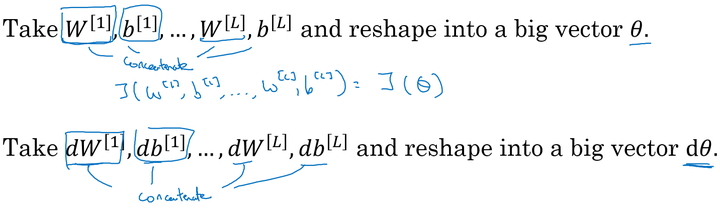
进行梯度检验:
进行如下图的梯度检验

判断 是否接近。
判断公式:
其中,“ ”表示欧几里得范数,它是误差平方之和,然后求平方根,得到的欧氏距离。
14、实现梯度检验 Notes
- 不要在训练过程中使用梯度检验,只在debug的时候使用,使用完毕关闭梯度检验的功能;
- 如果算法的梯度检验出现了错误,要检查每一项,找出错误,也就是说要找出哪个 dθ_approx[i] 与 dθ 的值相差比较大;
- 不要忘记了正则化项;
- 梯度检验不能与dropout同时使用。因为每次迭代的过程中,dropout会随机消除隐层单元的不同神经元,这时是难以计算dropout在梯度下降上的代价函数J;
- 在随机初始化的时候运行梯度检验,或许在训练几次后再进行。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2470290795@qq.com
文章标题:1深度学习的实用层面
文章字数:2.5k
本文作者:runze
发布时间:2020-02-16, 17:09:44
最后更新:2020-02-23, 08:30:23
原始链接:http://yoursite.com/2020/02/16/%E5%90%B4%E6%81%A9%E8%BE%BE%20%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/02%E6%94%B9%E5%96%84%E6%B7%B1%E5%B1%82%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%EF%BC%9A%E8%B6%85%E5%8F%82%E6%95%B0%E8%B0%83%E8%AF%95%E3%80%81%E6%AD%A3%E5%88%99%E5%8C%96%E4%BB%A5%E5%8F%8A%E4%BC%98%E5%8C%96/1%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%9A%84%E5%AE%9E%E7%94%A8%E5%B1%82%E9%9D%A2/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

