编程作业——优化Optimization

1 | import numpy as np |
Gradient Descent
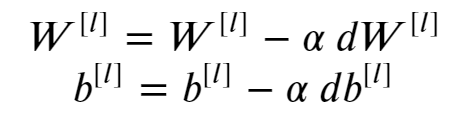
1 | def update_parameters_with_gd(parameters, grads, learning_rate): |
Mini-Batch Gradient descent
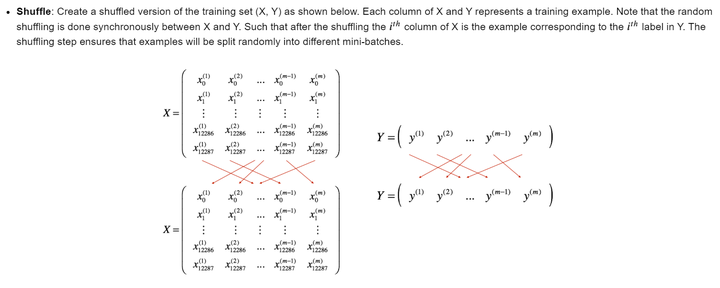
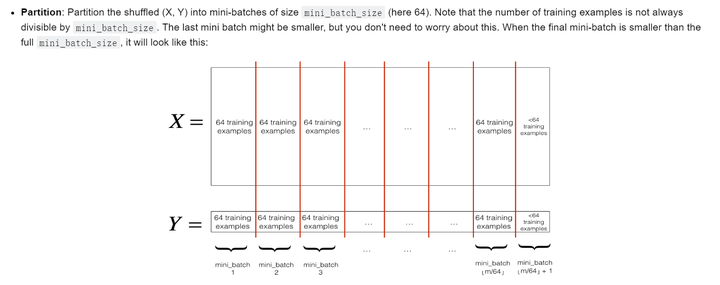
1 | def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0): |
Momentum
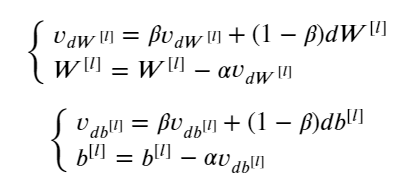
1 | def initialize_velocity(parameters): |
1 | def update_parameters_with_momentum(parameters, grads, v, beta, learning_rate): |
Adam
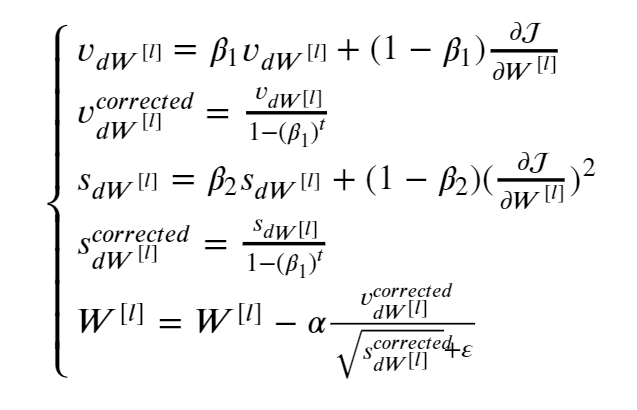
1 | def initialize_adam(parameters): |
1 | def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01, beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8): |
1 | train_X, train_Y = load_dataset() |
1 | def model(X, Y, layers_dims, optimizer, learning_rate = 0.0007, mini_batch_size = 64, beta = 0.9, |
Mini-batch Gradient descent
1 | # train 3-layer model |
Cost after epoch 0: 0.708983
Cost after epoch 1000: 0.659841
Cost after epoch 2000: 0.628205
Cost after epoch 3000: 0.571343
Cost after epoch 4000: 0.593195
Cost after epoch 5000: 0.503812
Cost after epoch 6000: 0.507677
Cost after epoch 7000: 0.494559
Cost after epoch 8000: 0.459184
Cost after epoch 9000: 0.399013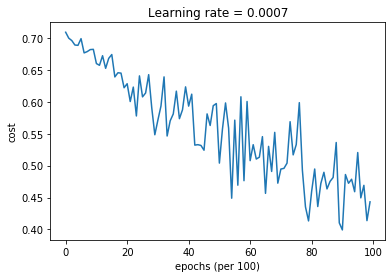
Accuracy: 0.7966666666666666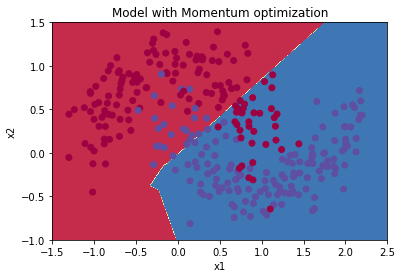
Mini-batch gradient descent with momentum
1 | # train 3-layer model |
Cost after epoch 0: 0.709029
Cost after epoch 1000: 0.659953
Cost after epoch 2000: 0.628344
Cost after epoch 3000: 0.571453
Cost after epoch 4000: 0.593252
Cost after epoch 5000: 0.503935
Cost after epoch 6000: 0.507794
Cost after epoch 7000: 0.494631
Cost after epoch 8000: 0.459387
Cost after epoch 9000: 0.399227
Accuracy: 0.7966666666666666
Mini-batch with Adam mode
1 | # train 3-layer model |
Cost after epoch 0: 0.700736
Cost after epoch 1000: 0.171262
Cost after epoch 2000: 0.119976
Cost after epoch 3000: 0.258917
Cost after epoch 4000: 0.079703
Cost after epoch 5000: 0.119927
Cost after epoch 6000: 0.150617
Cost after epoch 7000: 0.131514
Cost after epoch 8000: 0.159743
Cost after epoch 9000: 0.057505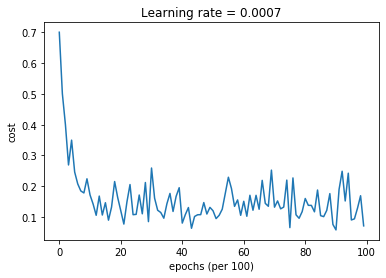
Accuracy: 0.93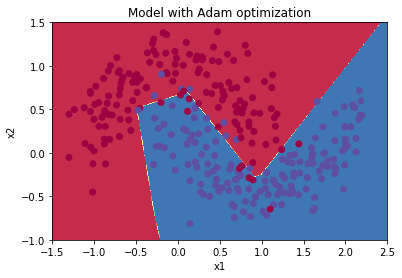
Summary
| **optimization method** | **accuracy** | **cost shape** | Gradient descent | 79.7% | oscillations |
| Momentum | 79.7% | oscillations |
| Adam | 94% | smoother |
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2470290795@qq.com
文章标题:编程作业——优化Optimization
文章字数:1.2k
本文作者:runze
发布时间:2020-02-18, 10:28:29
最后更新:2020-02-23, 08:31:01
原始链接:http://yoursite.com/2020/02/18/%E5%90%B4%E6%81%A9%E8%BE%BE%20%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/02%E6%94%B9%E5%96%84%E6%B7%B1%E5%B1%82%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%EF%BC%9A%E8%B6%85%E5%8F%82%E6%95%B0%E8%B0%83%E8%AF%95%E3%80%81%E6%AD%A3%E5%88%99%E5%8C%96%E4%BB%A5%E5%8F%8A%E4%BC%98%E5%8C%96/%E7%BC%96%E7%A8%8B%E4%BD%9C%E4%B8%9A%E2%80%94%E2%80%94%E4%BC%98%E5%8C%96Optimization/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

